Comment ingérer 100 Mrd. d’événements depuis des millions d’appareils par mois ?
Valentin
Tech Lead chez Pubstack
- Couteau suisse
- Co-fondateur & organisateur de Touraine Tech

- Formateur au CEFIM
- vmaerten.io
- @v_maerten
- vmaerten.bsky.social

Comment ingérer 100 Mrd. d’événements depuis des millions d’appareils par mois ?
Valentin
Tech Lead chez Pubstack
- Couteau suisse
- Co-fondateur & organisateur de Touraine Tech
- Formateur au CEFIM
- vmaerten.io
- @v_maerten
- vmaerten.bsky.social
Erwann
Tech Lead chez Pubstack
- Couteau suisse également
- Expérience variée : SRE, Ops, Big Data, …
- Erwann Cloarec
- @ErwannC

Pubstack
- Start-up créer en 2017 par 3 personnes.
- 50 personnes aujourd’hui.
- Collecte et analyse de données publicitaires pour de grand groupe média (Prisma, 366, Reworld, etc).
Les contraintes
Le principal focus des dev doit se tourner vers les besoins de nos clients, pas sur l’infrastructure.
- Doit pouvoir scaler automatiquement pour accueillir des données fluctuant dans la journée.
- Résilience (objectif 0 downtime)
- Couts maitrisés
Par jour :
- 4 milliards de requêtes http
- 650Go de donnée ingérée
- 3.5 milliards d’éléments uniques
- 150Go de données agrégées et indexées
L’infrastructure
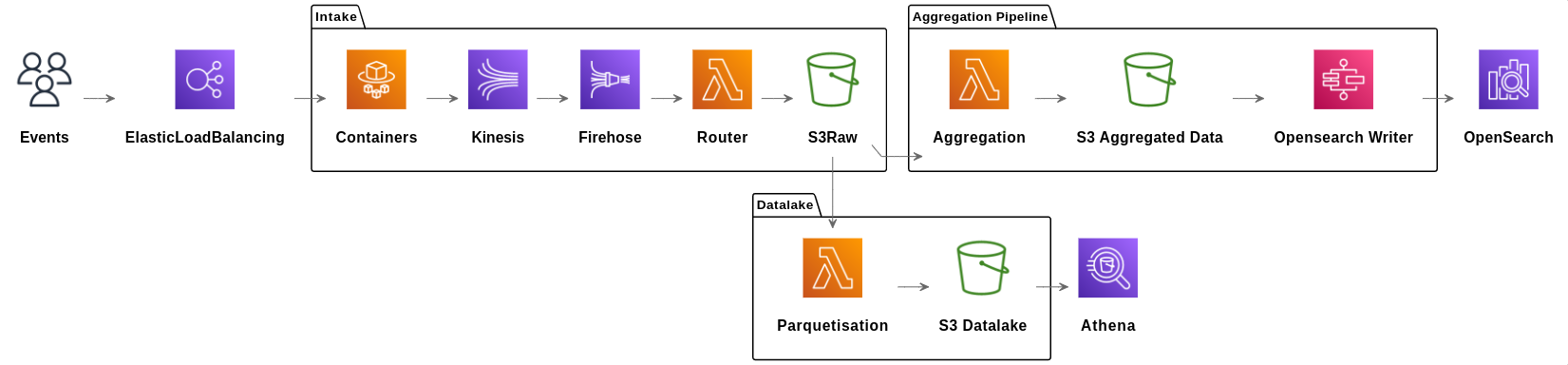
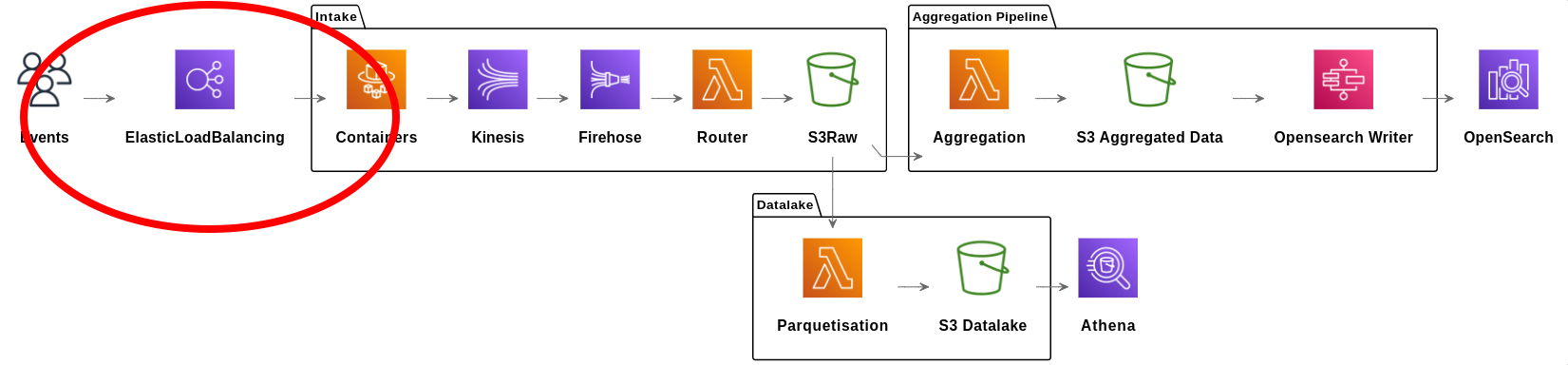
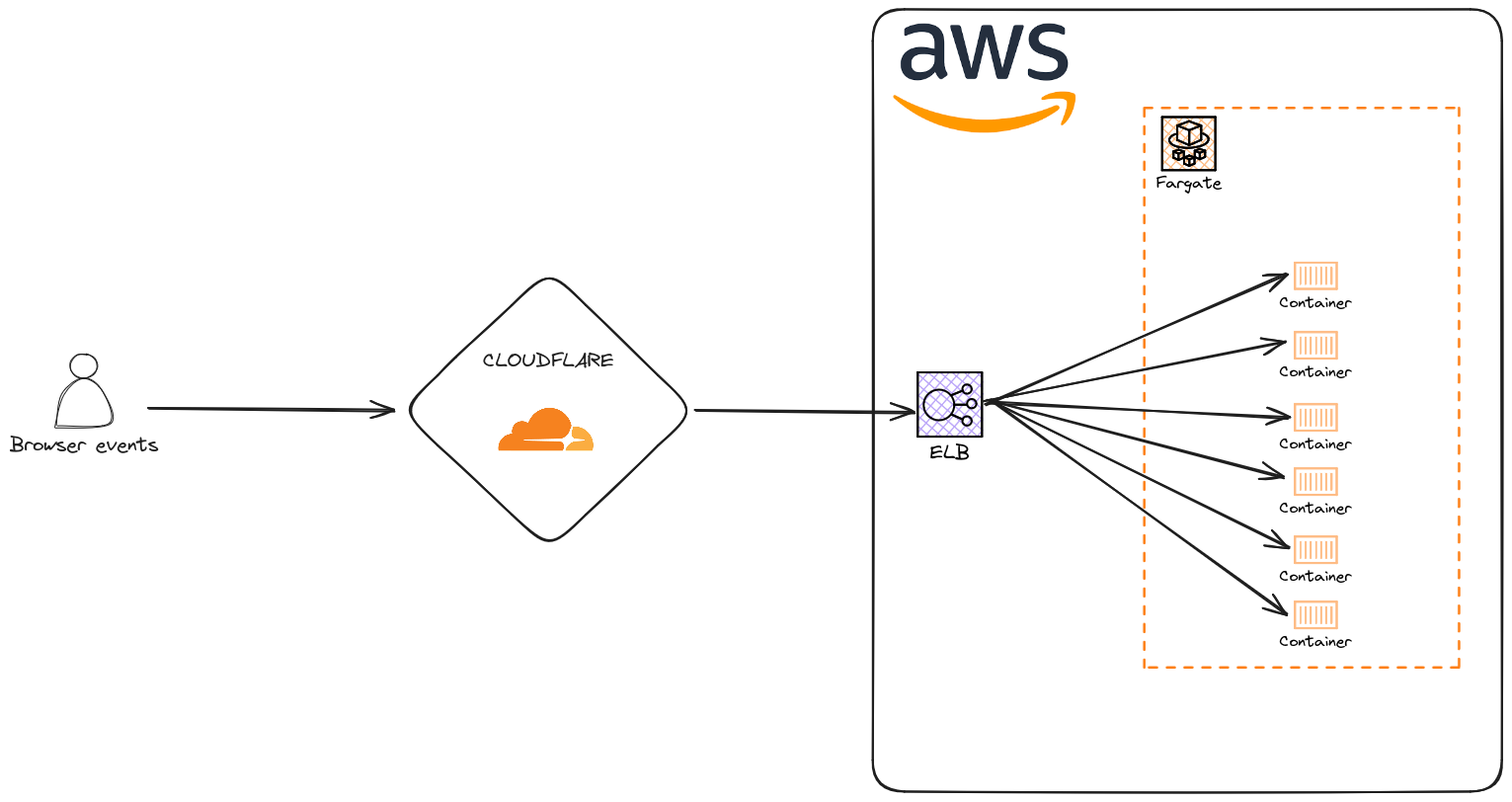
La réception de la donnée
CloudFlare
CloudFlare est un CDN qui permet de mettre en cache les requêtes http.
Pourquoi ?
- Beaucoup de requête sont les mêmes, on peut les mettre en cache.
- Réduire la charge sur nos services.
- Et donc réduire les couts.
- Pourquoi pas CloudFront ? => LE PRIX !
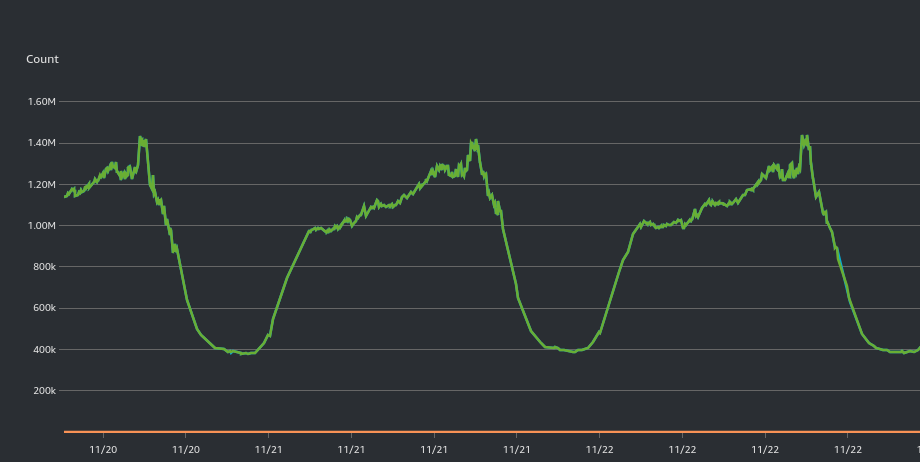
Quelques chiffres
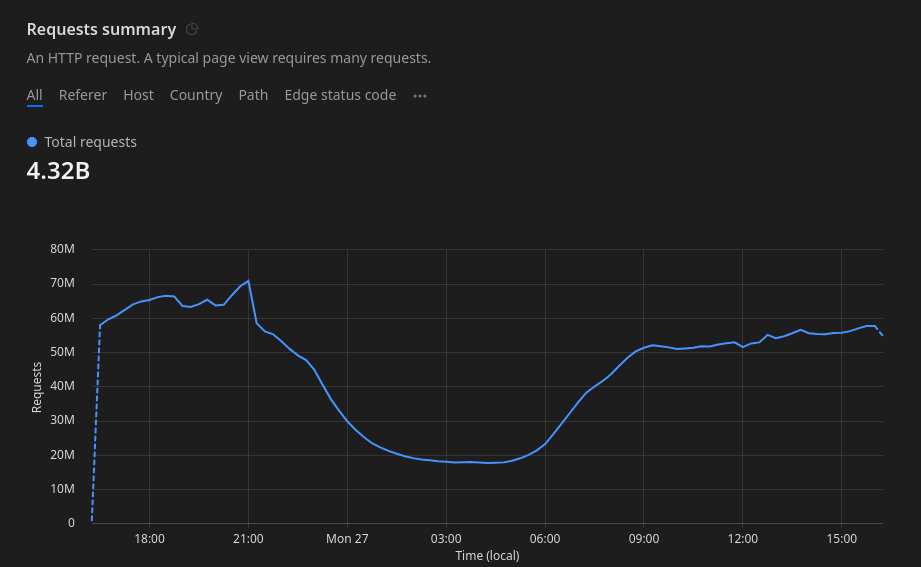
ALB
Application Load Balancer permet de lier une URL à un service ECS.
Point d’entrée de la donnée dans AWS, permet de distribuer le traffic parmi les conteneurs, et gère leur cycle de vie via les target groups.
La configuration permet de rediriger une route vers différents target groups.
ECS (Fargate)
ECS Fargate est un service managé qui permet de déployer des conteneurs Docker.
ECS vient avec un ensemble de feature d’orchestration : healthcheck, déploiement automatique, rolling update, autoscaling, …
Pourquoi ECS :
- Stateful : nous avons besoin de requêter DynamoDB et de garder la donnée.
- Autoscaling : gérer la fluctuation de la charge dans la journée.
- Rolling update : pas de downtime, le déploiement d’une nouvelle version est sans risque
Code Deploy
Permet de déployer une nouvelle version d’un service ECS de manière sûre.
Le blue/green deployment permet de déployer une nouvelle version et d’y rediriger le traffic progressivement, avec des métriques pour valider le déploiement à chaque étape.
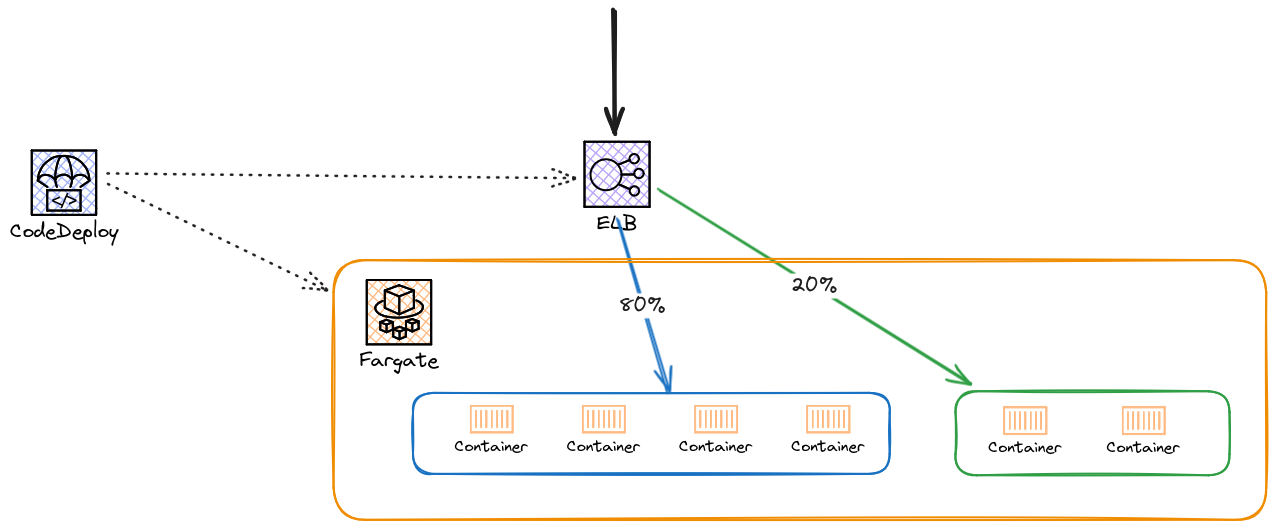
Et après ?
Format de donnée
De JSON (HTTP depuis notre collector) vers Protobuf.
Format de donnée binaire, plus léger que JSON, plus rapide à sérialiser/désérialiser. Développé par Google.
Nous avons choisi et gardé protobuf pour :
- le poids de la donnée
- le schéma by design
- la fiabilité de la sérialisation/désérialisation
- l’interopérabilité entre les langages (Go, Rust, JS, Python)
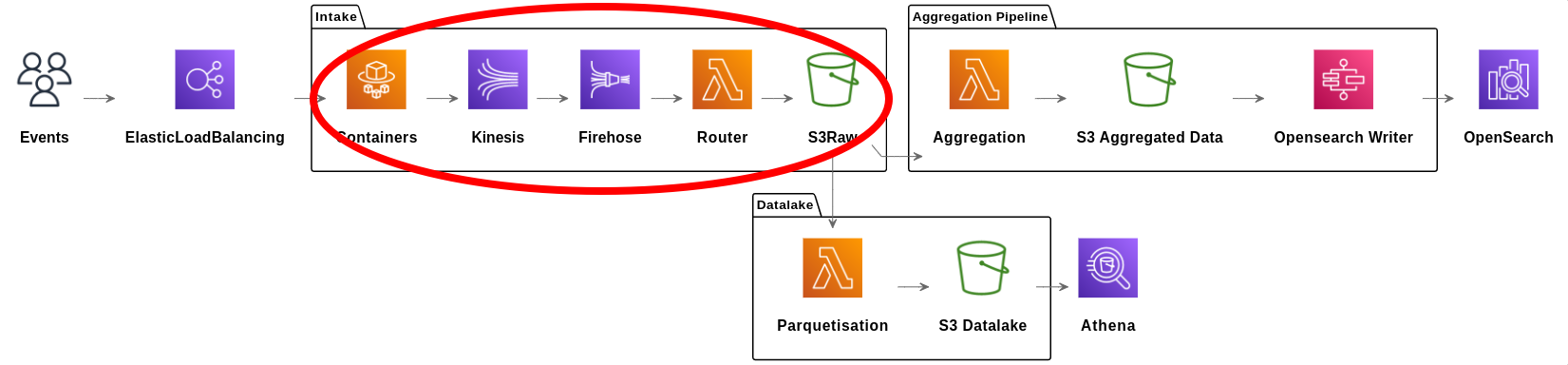
Kinesis Stream
Service de Pub/Sub entièrement managé.
On écrit la donnée rapidement, sans risque de perte et sans impact si la suite de la pipeline n’arrive pas à suivre.
Kinesis permet aux conteneurs de répondre très rapidement, même si le reste de la pipeline est en diffculté, voir même arrêtée.
La lecture peut être arrêtée et reprise sans impact.
Kinesis Firehose
Service de streaming vers S3, Redshift, ElasticSearch, …
Chargement de nos données en batch vers S3.
Le regroupement se fait selon une condition parmi :
- 128Mo de données
- 15min se sont écoulées depuis le dernier fichier.
Où et comment stocker toute cette donnée ?
La combinaison S3 et Lambda: gestion par événement simple
S3 est un service de stockage objet, Lambda permet de lancer du code sans serveur.
Nous utilisons beaucoup la combinaison S3 + Lambda chez Pubstack : déclencher du code quand un fichier est créé sur S3.
Quand un fichier est déposé sur S3, comme avec Firehose ou par une lambda, nous pouvons soit une lambda qui aura comme input le fichier.
La combinaison S3 et Lambda: gestion par événement SNS
SNS est un service de messagerie qui permet de déclencher des actions en fonction d’un évènement.
Certains use case nécessitent de déclencher plus d’une lambda pour un fichier déposé sur S3. Pour cela, nous utilisons SNS: un fichier déposé sur S3 déclenche un évènement SNS qui lui déclenche les lambdas.
C’est avec ce mécanisme que notre pipeline se sépare en 2 : une partie agrégation et une partie datalake qui vont se baser sur le même fichier S3.
Pipeline d’agrégation
Objectif : stocker la donnée dans Opensearch, le service managé forké d’Elasticsearch.
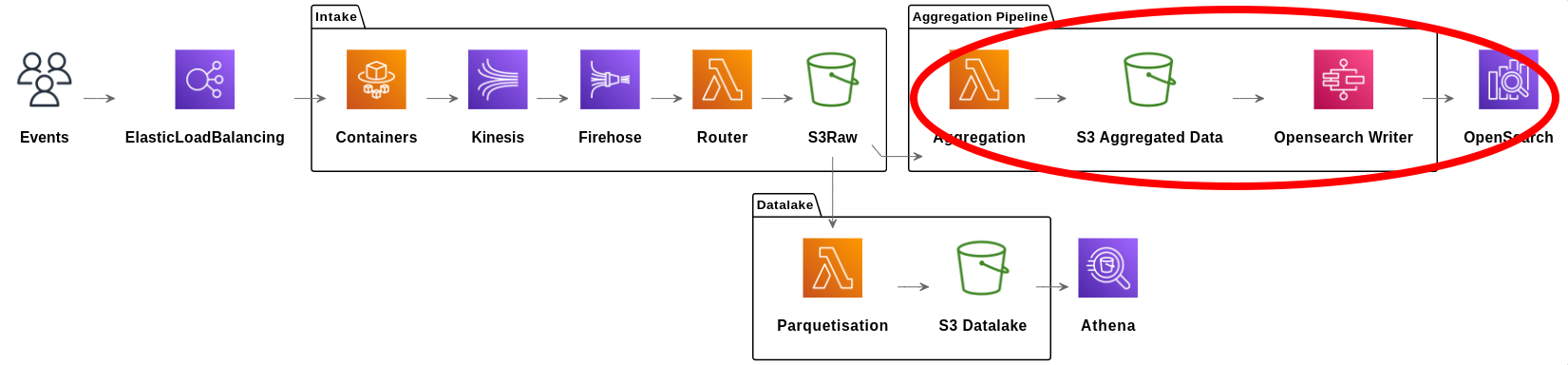
Deux étapes pour l’agrégation :
- Une lambda pour agréger la donnée et la stocker sur S3 au format JSON prêt à être envoyé à Opensearch.
- Une step function qui lance des Lambda afin d’écrire ces données sur Opensearch.
OpenSearch
- 13 machines (3 masters et 10 datas)
- masters : c5.xlarge.search
- datas : i3.2xlarge.search. Optimisé pour la lecture / écriture
- 1 index par jour
- sort des documents par "type" et par "client" (comme un index)
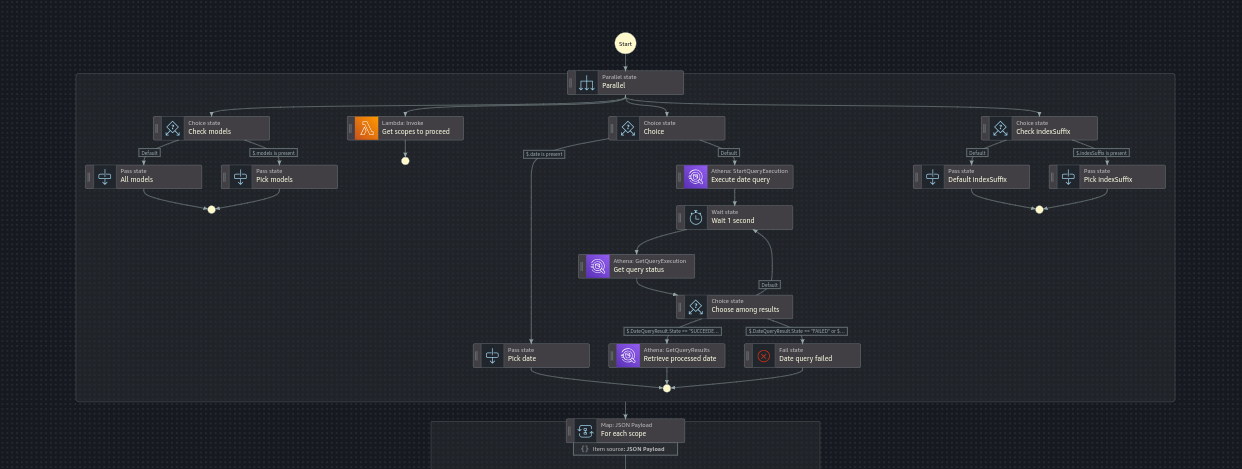
Daily aggregation
Objectif : avoir 93 jours de données disponibles dans l’App
- Pas besoin de la granularité à l’heure à partir de J+15
- "réagrégation" de la donnée à J+15
- Utilisation des Step Functions pour orchestrer le process
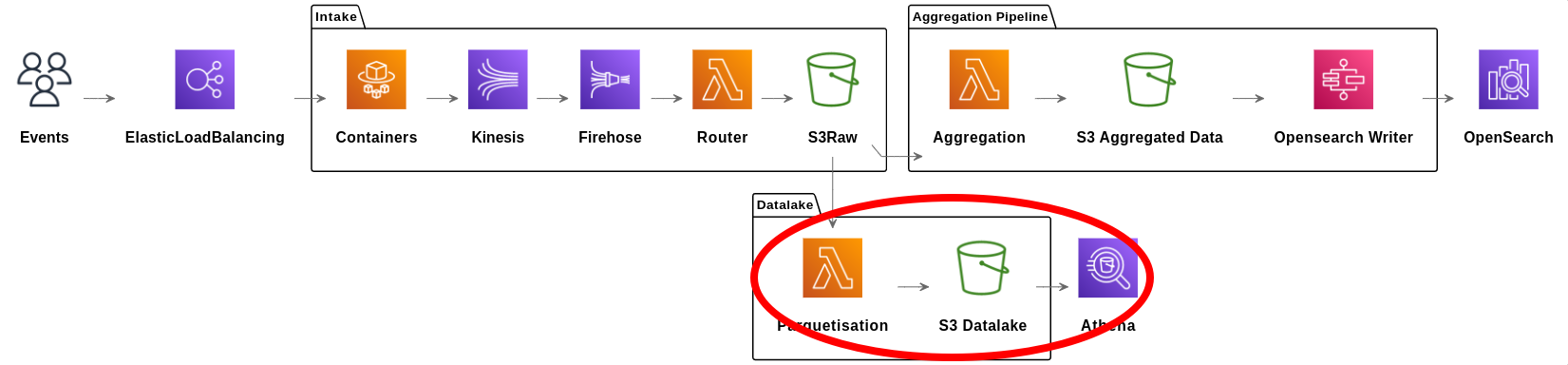
Pipeline du datalake
Enjeu: transformer le protobuf en fichiers requêtable
Datalake: stockage et format (1)
Objectif : stocker la donnée dans S3 pour qu’elle puisse être accessible pour les data analyst.
Nous utilisons le moteur Athena pour requêter nos données:
- Athena utilise Glue pour connaître les tables et leurs schemas
- Peut lire des fichiers stockés sur S3 sous différents formats (JSON, Parquet, CSV, ou un format custom)
Nous avons choisi le format orienté colonnes Parquet. C’est un format optimisé pour le stockage de larges datasets structurés. C’est un format de fichier binaire (et non texte comme le CSV ou le JSON).
Datalake: stockage et format (2)
C’est 1To par jour qui est ajouté dans S3.
Notre volumétrie impose de mettre en place une règle de cycle de vie et de passer la donnée de plus de 90 jours en Infrequent Access.
Le Infrequent Access permet un moindre coût de stockage, mais en contrepartie coûte plus cher à la lecture.
| S3 Storage Type | Storage pricing | Data Retrieval |
|---|---|---|
| S3 Standard | $0.023 / GB | N/A |
| S3 Infrequent Access | $0.0125 / GB | $0.01 / GB |
Datalake: stockage et format (3)
Ne requêter que les données utiles est un challenge : une requête peut coûter $300
Afin de ne pas scanner tous les fichiers à chaque requête, un partitionnement est nécessaire. Avec le passage de la donnée en IA, une partition sur le temps est nécessaire. Nous avons aussi une partition par client.
La modélisation de ce partitionnement est importante, car elle régit toutes les requêtes Athena, faites sur la donnée : une requête sans clause where sur les partitions équivaut à un scan entier de la table, et cela nous coûte très cher.
select * from auctions where jour='2023-12-04' and client='12354abcdef'select * from auctions where jour='2023-12-04' and client='12354abcdef'
Cette requête ne va requêter que les fichiers dans s3://datalake-bucket/jour="2023-12-04"/client="12354"/
Pipeline du datalake
Enjeu: transformer le protobuf en fichiers parquets
Encore le combo S3 + Lambda : les fichiers bruts au format protobuf sont découpés en fichiers parquets par jour et par client (pour le partitionnement).
Problème: ces fichiers sont bien souvent trop petits, et pour les gros clients, trop nombreux. Pour des performances idéales de requête avec Athena, les fichiers parquets ont une taille d’environ 128Mo.
Solution: une pipeline de concaténation de fichiers parquets. Tous les jours des Lambda sont lancées pour concaténer les fichiers parquet afin d’atteindre une taille d’environ 128Mo.
IAM (Identity and Access Management)
Sécuriser les accès aux ressources AWS (DynamoDB, S3, Lambda, etc)
- Un rôle par lambda
- Permissions à petite granularité
- Identity Center SSO pour les utilisateurs
Le monitoring
Cloudwatch
CloudWatch est un service de monitoring, de gestion de metrics et de gestion des logs.
Cloudwatch nous permet de stocker, et requêter tous nos logs.
Il nous permet aussi de mettre des alarms en fonction d’un certain pattern de log et d’être alerté en cas de problème.
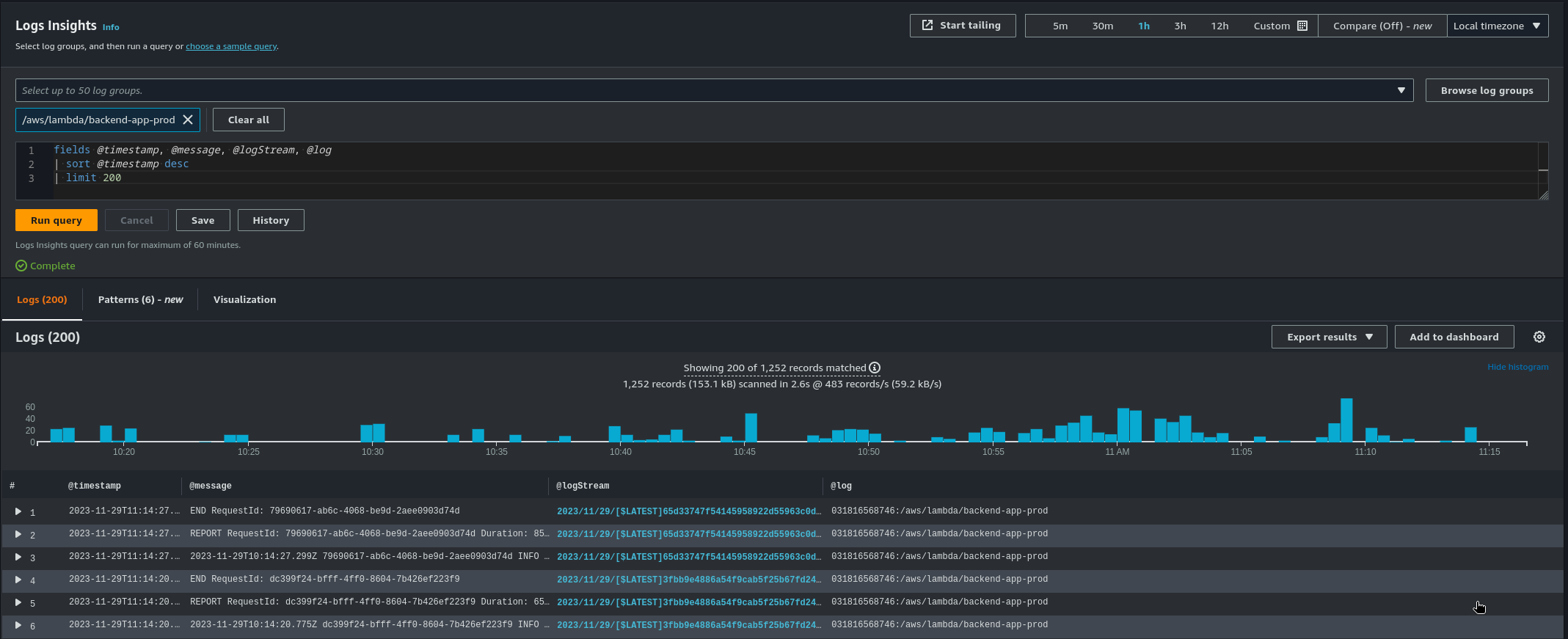
Cloudwatch Dashboard
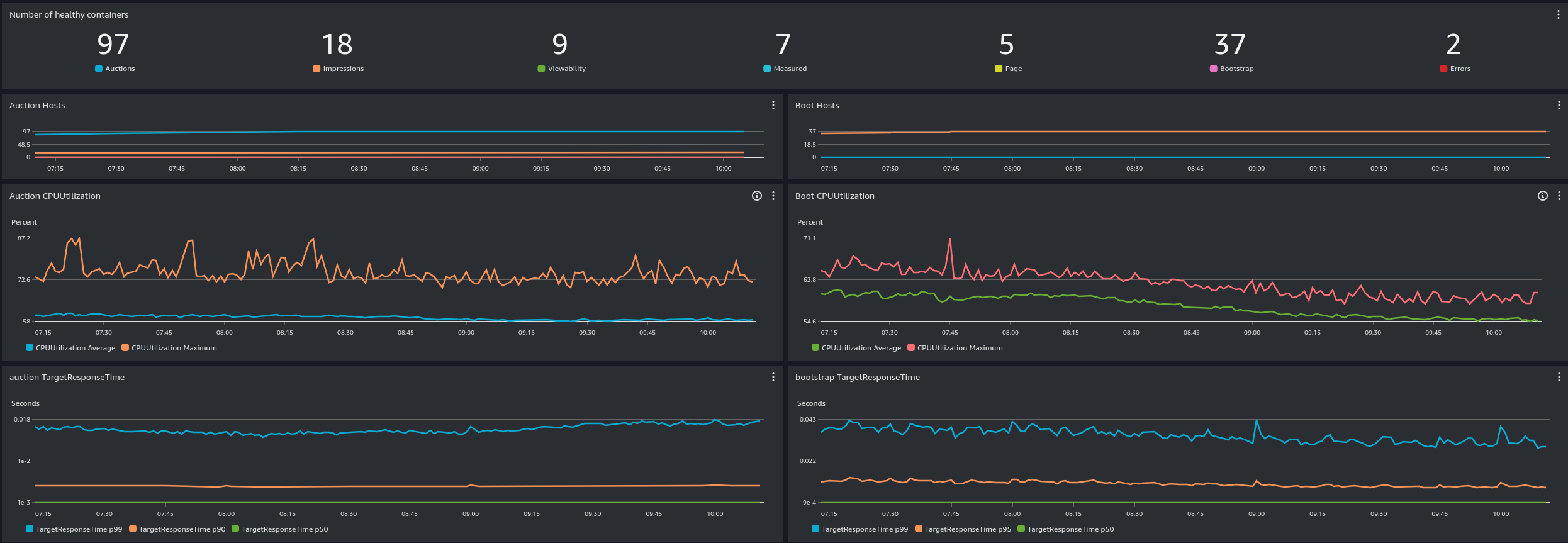
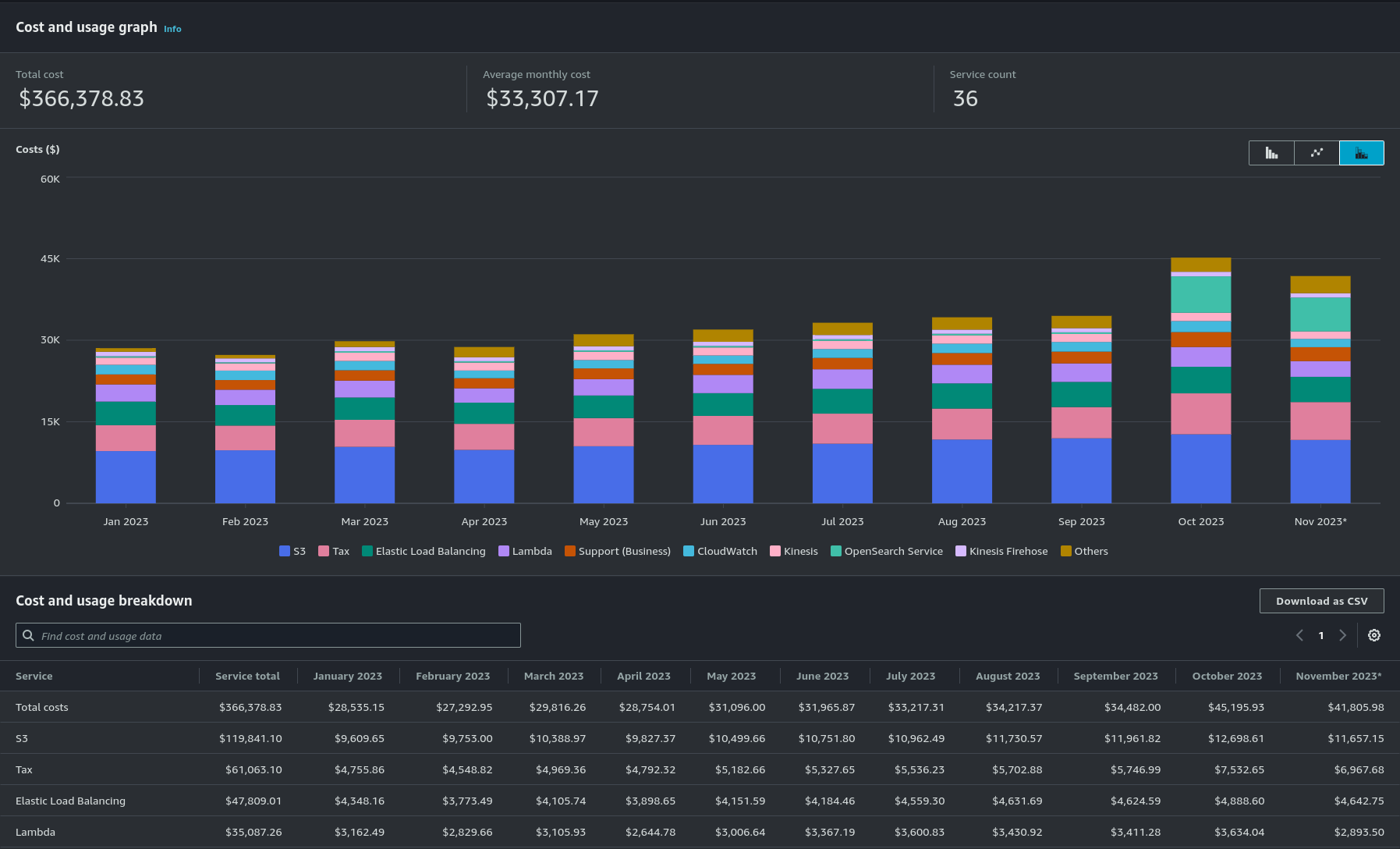
Le Cost Explorer
Cost Explorer est un outil de visualisation et d’analyse des coûts permettant aux utilisateurs de comprendre et de gérer les dépenses liées aux services AWS.
Cela nous permet de suivre l’évolution de nos couts jour par jour, projet par projet ainsi que service par service.
Nous nous servons beaucoup des tags sur AWS afin de pouvoir filter plus facilement dans le Cost Explorer.
Le Cost Explorer
Comment deployer tout ça ?
Terraform
Terraform est un outil d’Infrastructure as Code (IaC) développé par Hashicorp.
Cela permet de décrire son infrastructure dans un fichier texte, et de la déployer de manière reproductible.
- Fichier .tf
- Fonctionne avec un state
- Faire un triple diff entre le code, le state et l’infrastructure réelle
- Éviter les erreurs humaines
- Pas besoin de définir les dépendances entre les ressources
resource "aws_lambda_function" "my_lambda" { filename = "myLambda.zip" function_name = "myLambda" handler = "index.handler" source_code_hash = filebase64sha256("myLambda.zip") runtime = "nodejs16.x" memory_size = 1024 timeout = 900 environment {} }resource "aws_lambda_function" "my_lambda" { filename = "myLambda.zip" function_name = "myLambda" handler = "index.handler" source_code_hash = filebase64sha256("myLambda.zip") runtime = "nodejs16.x" memory_size = 1024 timeout = 900 environment {} }
Conclusion
AWS nous permet de gérer une infrastructure complexe, de manière scalable et résiliente.
Nous passons très peu de temps à configurer, tuner ou refactorer notre infrastructure. AWS peut coûter cher, mais nous permet de nous concentrer sur notre métier. Nous ne faisons jamais de SSH, pas de machine à maintenir.
Un désavantage fort est le "vendor-locking" -> nous sommes liés à AWS. Mais c’est fait en toute connaissance de cause.
Merci
Des questions ?
Valentin
Erwann
Feedback
